How To Restart Your Server
Overview
This page outlines the steps to restart a customer-managed multi-server installation. Read these instructions in their entirety before beginning the restart process.
Kubernetes commands refer to servers as “nodes”; as such, this document will do the same.
Process
- Connect to the first node in your maintenance window and open a command prompt.
- Run the following command to get the list of deployments in the ingress-nginx namespace:
kubectl get deployment -n ingress-nginx - Ensure your Nginx Ingress controller is scaled to a minimum of two replicas. Verify this by confirming that the Available column for the ingress-nginx-controller has a minimum value of 2.
NAME READY UP-TO-DATE AVAILABLE AGE ingress-nginx-controller 2/2 2 2 20d - Run the following command to get a list of all nodes in the cluster:
Ensure that the Status column displays a value of Ready for each node.
$ kubectl get nodes

- Run the command below to cordon off the first of the nodes you are NOT currently connected to. This prevents any new pods from being scheduled on the cordoned node.
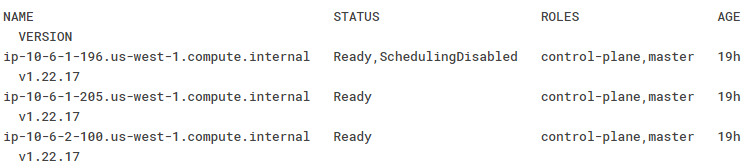
$ kubectl cordon [NAME] - Retrieve the nodes again to ensure the cordon has been completed successfully by running the following command:
If the cordon was successful, the Status column will display a Ready, SchedulingDisabled value for the cordoned node.
$ kubectl get nodes
- Run the command below to drain the cordoned node. This will evict all pods that are not part of daemonsets from the drained node. Kubernetes will attempt to put the pods onto one of the other nodes in the cluster (barring resource and affinity constraints).
$ kubectl drain [NAME] --ignore-daemonsets --delete-emptydir-data - Run the following commands to ensure that the Kinetic Platform is still running:
$ kubectl get pods -A -l platform.kineticdata.com/component=task -o wide $ kubectl get pods -n kinetic -o wide $ kubectl get pods -n ingress-nginx -o wide - For each command you run in Step 6, check the Ready column. Ensure it contains a value of X/Y, where X and Y are the same number. This indicates that all containers are up.
- For each command you run in Step 6, ensure the Node column does not contain the node we cordoned and drained. The one exception to this is the
log-collectornode, as it is a daemonset and will always be present on every node in the cluster.

- Optional: We recommend removing the node from the Load Balancer. This guarantees no traffic is being sent to the node being restarted.
- Follow your usual maintenance process to restart the node you cordoned and drained.
- Run the following command to monitor the status of each node:
kubectl get nodes -w - Ensure that the node you restarted displays a Status of NotReady, SchedulingDisabled. Do not make any additional changes until the status of the restarted node changes to Ready.
- Run the following command to uncordon the restarted node:
$ kubectl uncordon [NAME] - If you removed the node from the Load Balancer in Step 9, re-add the node back into the Load Balancer.
- Repeat Steps 1 through 14 for each additional node in your maintenance cycle.
Make sure you shell into a different node before repeating the above steps for the node you shelled into in Step 1.
Updated 9 months ago
Did this page help you?